在 Kubernetes 中,调度 (scheduling) 指的是确保 Pod 匹配到合适的节点, 以便 kubelet 能够运行它们。抢占 (Preemption) 指的是终止低优先级的 Pod 以便高优先级的 Pod 可以调度运行的过程。驱逐 (Eviction) 是在资源匮乏的节点上,主动让一个或多个 Pod 失效的过程。
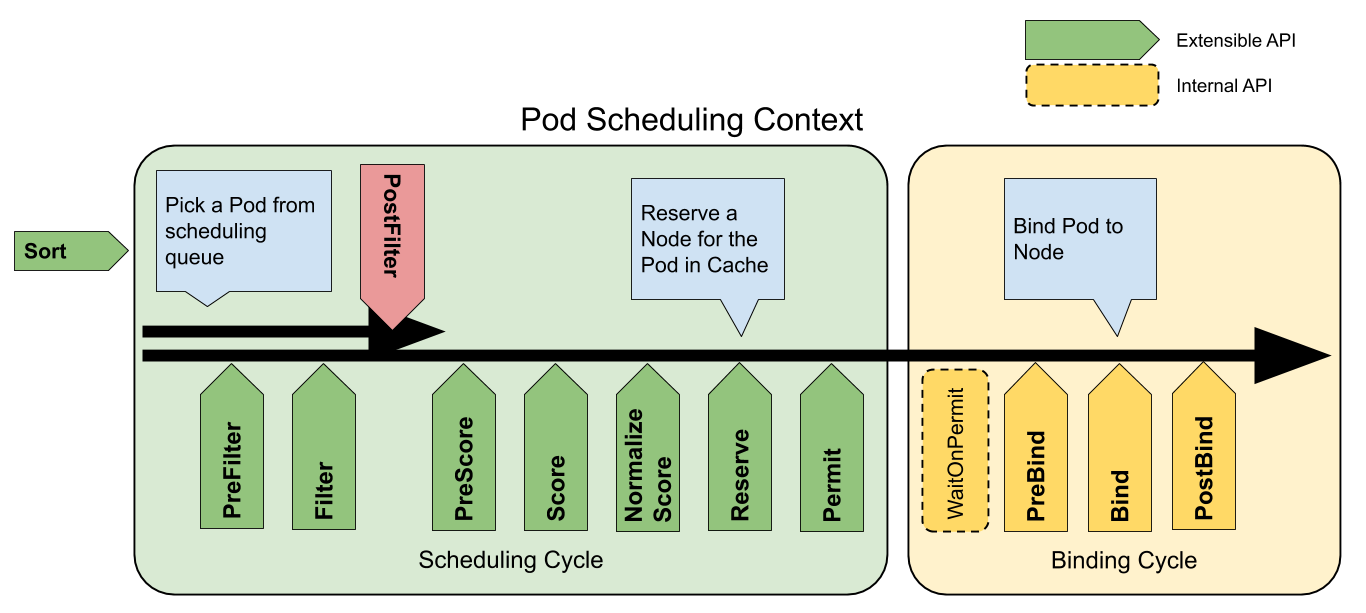
Kube-scheduler 选择一个最佳节点来运行新创建的或尚未调度(unscheduled)的 Pod。
由于 Pod 中的容器和 Pod 本身可能有不同的要求,调度程序会过滤掉任何不满足 Pod 特定调度需求的节点。
或者,API 允许你在创建 Pod 时为它指定一个节点,但这并不常见,并且仅在特殊情况下才会这样做。
在一个集群中,满足一个 Pod 调度请求的所有节点称之为 可调度节点。
如果没有任何一个节点能满足 Pod 的资源请求,
那么这个 Pod 将一直停留在未调度状态直到调度器能够找到合适的 Node。
调度器先在集群中找到一个 Pod 的所有可调度节点,然后根据一系列函数对这些可调度节点打分,
选出其中得分最高的节点来运行 Pod。之后,调度器将这个调度决定通知给
kube-apiserver,这个过程叫做 绑定。
过滤阶段会将所有满足 Pod 调度需求的节点选出来。
例如,PodFitsResources 过滤函数会检查候选节点的可用资源能否满足 Pod 的资源请求。
在过滤之后,得出一个节点列表,里面包含了所有可调度节点;通常情况下,
这个节点列表包含不止一个节点。如果这个列表是空的,代表这个 Pod 不可调度。
在打分阶段,调度器会为 Pod 从所有可调度节点中选取一个最合适的节点。
根据当前启用的打分规则,调度器会给每一个可调度节点进行打分。
最后,kube-scheduler 会将 Pod 调度到得分最高的节点上。
如果存在多个得分最高的节点,kube-scheduler 会从中随机选取一个。
你可以约束一个 Pod
以便 限制 其只能在特定的节点上运行,
或优先在特定的节点上运行。
有几种方法可以实现这点,推荐的方法都是用
标签选择算符来进行选择。
通常这样的约束不是必须的,因为调度器将自动进行合理的放置(比如,将 Pod 分散到节点上,
而不是将 Pod 放置在可用资源不足的节点上等等)。但在某些情况下,你可能需要进一步控制
Pod 被部署到哪个节点。例如,确保 Pod 最终落在连接了 SSD 的机器上,
或者将来自两个不同的服务且有大量通信的 Pods 被放置在同一个可用区。
本示例定义了一条 Pod 亲和性规则和一条 Pod 反亲和性规则。Pod 亲和性规则配置为
requiredDuringSchedulingIgnoredDuringExecution,而 Pod 反亲和性配置为
preferredDuringSchedulingIgnoredDuringExecution。
亲和性规则表示,仅当节点和至少一个已运行且有 security=S1 的标签的
Pod 处于同一区域时,才可以将该 Pod 调度到节点上。
更确切的说,调度器必须将 Pod 调度到具有 topology.kubernetes.io/zone=V
标签的节点上,并且集群中至少有一个位于该可用区的节点上运行着带有
security=S1 标签的 Pod。
反亲和性规则表示,如果节点处于 Pod 所在的同一可用区且至少一个 Pod 具有
security=S2 标签,则该 Pod 不应被调度到该节点上。
更确切地说, 如果同一可用区中存在其他运行着带有 security=S2 标签的 Pod 节点,
并且节点具有标签 topology.kubernetes.io/zone=R,Pod 不能被调度到该节点上。
Pod 一旦创建就被认为准备好进行调度。
Kubernetes 调度程序尽职尽责地寻找节点来放置所有待处理的 Pod。
然而,在实际环境中,会有一些 Pod 可能会长时间处于"缺少必要资源"状态。
这些 Pod 实际上以一种不必要的方式扰乱了调度器(以及下游的集成方,如 Cluster AutoScaler)。
通过指定或删除 Pod 的 .spec.schedulingGates,可以控制 Pod 何时准备好被纳入考量进行调度。
配置 Pod schedulingGates
schedulingGates 字段包含一个字符串列表,每个字符串文字都被视为 Pod 在被认为可调度之前应该满足的标准。
该字段只能在创建 Pod 时初始化(由客户端创建,或在准入期间更改)。
创建后,每个 schedulingGate 可以按任意顺序删除,但不允许添加新的调度门控。
s1
s1 --> if
s2 --> if: scheduling gate removed
if --> s2: no
if --> s3: yes
s3 --> s4
s4 --> [*]
-->
stateDiagram-v2
s1: 创建 Pod
s2: Pod 调度门控
s3: Pod 调度就绪
s4: Pod 运行
if: 调度门控为空?
[*] --> s1
s1 --> if
s2 --> if: 移除了调度门控
if --> s2: 否
if --> s3: 是
s3 --> s4
s4 --> [*]
labelSelector 用于查找匹配的 Pod。匹配此标签的 Pod 将被统计,以确定相应拓扑域中 Pod 的数量。
有关详细信息,请参考标签选择算符。
matchLabelKeys 是一个 Pod 标签键的列表,用于选择需要计算分布方式的 Pod 集合。
这些键用于从 Pod 标签中查找值,这些键值标签与 labelSelector 进行逻辑与运算,以选择一组已有的 Pod,
通过这些 Pod 计算新来 Pod 的分布方式。Pod 标签中不存在的键将被忽略。
null 或空列表意味着仅与 labelSelector 匹配。
位于这些节点上的 Pod 不影响 maxSkew 计算,在上面的例子中,假设节点 node1 没有标签 "zone",
则 2 个 Pod 将被忽略,因此新来的 Pod 将被调度到可用区 A 中。
新的 Pod 没有机会被调度到这类节点上。在上面的例子中,
假设节点 node5 带有 拼写错误的 标签 zone-typo: zoneC(且没有设置 zone 标签)。
节点 node5 接入集群之后,该节点将被忽略且针对该工作负载的 Pod 不会被调度到那里。
注意,如果新 Pod 的 topologySpreadConstraints[*].labelSelector 与自身的标签不匹配,将会发生什么。
在上面的例子中,如果移除新 Pod 的标签,则 Pod 仍然可以放置到可用区 B 中的节点上,因为这些约束仍然满足。
然而,在放置之后,集群的不平衡程度保持不变。可用区 A 仍然有 2 个 Pod 带有标签 foo: bar,
而可用区 B 有 1 个 Pod 带有标签 foo: bar。如果这不是你所期望的,
更新工作负载的 topologySpreadConstraints[*].labelSelector 以匹配 Pod 模板中的标签。
集群级别的默认约束
为集群设置默认的拓扑分布约束也是可能的。默认拓扑分布约束在且仅在以下条件满足时才会被应用到 Pod 上:
Pod 没有在其 .spec.topologySpreadConstraints 中定义任何约束。
Pod 隶属于某个 Service、ReplicaSet、StatefulSet 或 ReplicationController。
你可以给一个节点添加多个污点,也可以给一个 Pod 添加多个容忍度设置。
Kubernetes 处理多个污点和容忍度的过程就像一个过滤器:从一个节点的所有污点开始遍历,
过滤掉那些 Pod 中存在与之相匹配的容忍度的污点。余下未被过滤的污点的 effect 值决定了
Pod 是否会被分配到该节点。需要注意以下情况:
如果未被忽略的污点中存在至少一个 effect 值为 NoSchedule 的污点,
则 Kubernetes 不会将 Pod 调度到该节点。
配置了 preemptionPolicy: Never 的 Pod 将被放置在调度队列中较低优先级 Pod 之前,
但它们不能抢占其他 Pod。等待调度的非抢占式 Pod 将留在调度队列中,直到有足够的可用资源,
它才可以被调度。非抢占式 Pod,像其他 Pod 一样,受调度程序回退的影响。
这意味着如果调度程序尝试这些 Pod 并且无法调度它们,它们将以更低的频率被重试,
从而允许其他优先级较低的 Pod 排在它们之前。
非抢占式 Pod 仍可能被其他高优先级 Pod 抢占。
preemptionPolicy 默认为 PreemptLowerPriority,
这将允许该 PriorityClass 的 Pod 抢占较低优先级的 Pod(现有默认行为也是如此)。
如果 preemptionPolicy 设置为 Never,则该 PriorityClass 中的 Pod 将是非抢占式的。
数据科学工作负载是一个示例用例。用户可以提交他们希望优先于其他工作负载的作业,
但不希望因为抢占运行中的 Pod 而导致现有工作被丢弃。
设置为 preemptionPolicy: Never 的高优先级作业将在其他排队的 Pod 之前被调度,
只要足够的集群资源“自然地”变得可用。
非抢占式 PriorityClass 示例
apiVersion:scheduling.k8s.io/v1kind:PriorityClassmetadata:name:high-priority-nonpreemptingvalue:1000000preemptionPolicy:NeverglobalDefault:falsedescription:"This priority class will not cause other pods to be preempted."
当启用 Pod 优先级时,调度程序会按优先级对悬决 Pod 进行排序,
并且每个悬决的 Pod 会被放置在调度队列中其他优先级较低的悬决 Pod 之前。
因此,如果满足调度要求,较高优先级的 Pod 可能会比具有较低优先级的 Pod 更早调度。
如果无法调度此类 Pod,调度程序将继续并尝试调度其他较低优先级的 Pod。
抢占
Pod 被创建后会进入队列等待调度。
调度器从队列中挑选一个 Pod 并尝试将它调度到某个节点上。
如果没有找到满足 Pod 的所指定的所有要求的节点,则触发对悬决 Pod 的抢占逻辑。
让我们将悬决 Pod 称为 P。抢占逻辑试图找到一个节点,
在该节点中删除一个或多个优先级低于 P 的 Pod,则可以将 P 调度到该节点上。
如果找到这样的节点,一个或多个优先级较低的 Pod 会被从节点中驱逐。
被驱逐的 Pod 消失后,P 可以被调度到该节点上。
用户暴露的信息
当 Pod P 抢占节点 N 上的一个或多个 Pod 时,
Pod P 状态的 nominatedNodeName 字段被设置为节点 N 的名称。
该字段帮助调度程序跟踪为 Pod P 保留的资源,并为用户提供有关其集群中抢占的信息。
请注意,Pod P 不一定会调度到“被提名的节点(Nominated Node)”。
调度程序总是在迭代任何其他节点之前尝试“指定节点”。
在 Pod 因抢占而牺牲时,它们将获得体面终止期。
如果调度程序正在等待牺牲者 Pod 终止时另一个节点变得可用,
则调度程序可以使用另一个节点来调度 Pod P。
因此,Pod 规约中的 nominatedNodeName 和 nodeName 并不总是相同。
此外,如果调度程序抢占节点 N 上的 Pod,但随后比 Pod P 更高优先级的 Pod 到达,
则调度程序可能会将节点 N 分配给新的更高优先级的 Pod。
在这种情况下,调度程序会清除 Pod P 的 nominatedNodeName。
通过这样做,调度程序使 Pod P 有资格抢占另一个节点上的 Pod。
抢占的限制
被抢占牺牲者的体面终止
当 Pod 被抢占时,牺牲者会得到他们的
体面终止期。
它们可以在体面终止期内完成工作并退出。如果它们不这样做就会被杀死。
这个体面终止期在调度程序抢占 Pod 的时间点和待处理的 Pod (P)
可以在节点 (N) 上调度的时间点之间划分出了一个时间跨度。
同时,调度器会继续调度其他待处理的 Pod。当牺牲者退出或被终止时,
调度程序会尝试在待处理队列中调度 Pod。
因此,调度器抢占牺牲者的时间点与 Pod P 被调度的时间点之间通常存在时间间隔。
为了最小化这个差距,可以将低优先级 Pod 的体面终止时间设置为零或一个小数字。
支持 PodDisruptionBudget,但不保证
PodDisruptionBudget
(PDB) 允许多副本应用程序的所有者限制因自愿性质的干扰而同时终止的 Pod 数量。
Kubernetes 在抢占 Pod 时支持 PDB,但对 PDB 的支持是基于尽力而为原则的。
调度器会尝试寻找不会因被抢占而违反 PDB 的牺牲者,但如果没有找到这样的牺牲者,
抢占仍然会发生,并且即使违反了 PDB 约束也会删除优先级较低的 Pod。
与低优先级 Pod 之间的 Pod 间亲和性
只有当这个问题的答案是肯定的时,才考虑在一个节点上执行抢占操作:
“如果从此节点上删除优先级低于悬决 Pod 的所有 Pod,悬决 Pod 是否可以在该节点上调度?”
说明:
抢占并不一定会删除所有较低优先级的 Pod。
如果悬决 Pod 可以通过删除少于所有较低优先级的 Pod 来调度,
那么只有一部分较低优先级的 Pod 会被删除。
即便如此,上述问题的答案必须是肯定的。
如果答案是否定的,则不考虑在该节点上执行抢占。
如果悬决 Pod 与节点上的一个或多个较低优先级 Pod 具有 Pod 间亲和性,
则在没有这些较低优先级 Pod 的情况下,无法满足 Pod 间亲和性规则。
在这种情况下,调度程序不会抢占节点上的任何 Pod。
相反,它寻找另一个节点。调度程序可能会找到合适的节点,
也可能不会。无法保证悬决 Pod 可以被调度。
我们针对此问题推荐的解决方案是仅针对同等或更高优先级的 Pod 设置 Pod 间亲和性。
跨节点抢占
假设正在考虑在一个节点 N 上执行抢占,以便可以在 N 上调度待处理的 Pod P。
只有当另一个节点上的 Pod 被抢占时,P 才可能在 N 上变得可行。
下面是一个例子:
正在考虑将 Pod P 调度到节点 N 上。
Pod Q 正在与节点 N 位于同一区域的另一个节点上运行。
Pod P 与 Pod Q 具有 Zone 维度的反亲和(topologyKey:topology.kubernetes.io/zone)。
Pod P 与 Zone 中的其他 Pod 之间没有其他反亲和性设置。
为了在节点 N 上调度 Pod P,可以抢占 Pod Q,但调度器不会进行跨节点抢占。
因此,Pod P 将被视为在节点 N 上不可调度。
如果将 Pod Q 从所在节点中移除,则不会违反 Pod 间反亲和性约束,
并且 Pod P 可能会被调度到节点 N 上。
如果有足够的需求,并且如果我们找到性能合理的算法,
我们可能会考虑在未来版本中添加跨节点抢占。
故障排除
Pod 优先级和抢占可能会产生不必要的副作用。以下是一些潜在问题的示例以及处理这些问题的方法。
Pod 被不必要地抢占
抢占在资源压力较大时从集群中删除现有 Pod,为更高优先级的悬决 Pod 腾出空间。
如果你错误地为某些 Pod 设置了高优先级,这些无意的高优先级 Pod 可能会导致集群中出现抢占行为。
Pod 优先级是通过设置 Pod 规约中的 priorityClassName 字段来指定的。
优先级的整数值然后被解析并填充到 podSpec 的 priority 字段。
为了解决这个问题,你可以将这些 Pod 的 priorityClassName 更改为使用较低优先级的类,
或者将该字段留空。默认情况下,空的 priorityClassName 解析为零。
当 Pod 被抢占时,集群会为被抢占的 Pod 记录事件。只有当集群没有足够的资源用于 Pod 时,
才会发生抢占。在这种情况下,只有当悬决 Pod(抢占者)的优先级高于受害 Pod 时才会发生抢占。
当没有悬决 Pod,或者悬决 Pod 的优先级等于或低于牺牲者时,不得发生抢占。
如果在这种情况下发生抢占,请提出问题。
有 Pod 被抢占,但抢占者并没有被调度
当 Pod 被抢占时,它们会收到请求的体面终止期,默认为 30 秒。
如果受害 Pod 在此期限内没有终止,它们将被强制终止。
一旦所有牺牲者都离开,就可以调度抢占者 Pod。
在抢占者 Pod 等待牺牲者离开的同时,可能某个适合同一个节点的更高优先级的 Pod 被创建。
在这种情况下,调度器将调度优先级更高的 Pod 而不是抢占者。
这是预期的行为:具有较高优先级的 Pod 应该取代具有较低优先级的 Pod。
优先级较高的 Pod 在优先级较低的 Pod 之前被抢占
调度程序尝试查找可以运行悬决 Pod 的节点。如果没有找到这样的节点,
调度程序会尝试从任意节点中删除优先级较低的 Pod,以便为悬决 Pod 腾出空间。
如果具有低优先级 Pod 的节点无法运行悬决 Pod,
调度器可能会选择另一个具有更高优先级 Pod 的节点(与其他节点上的 Pod 相比)进行抢占。
牺牲者的优先级必须仍然低于抢占者 Pod。
当有多个节点可供执行抢占操作时,调度器会尝试选择具有一组优先级最低的 Pod 的节点。
但是,如果此类 Pod 具有 PodDisruptionBudget,当它们被抢占时,
则会违反 PodDisruptionBudget,那么调度程序可能会选择另一个具有更高优先级 Pod 的节点。
当存在多个节点抢占且上述场景均不适用时,调度器会选择优先级最低的节点。
Pod 优先级和服务质量之间的相互作用
Pod 优先级和 QoS 类
是两个正交特征,交互很少,并且对基于 QoS 类设置 Pod 的优先级没有默认限制。
调度器的抢占逻辑在选择抢占目标时不考虑 QoS。
抢占会考虑 Pod 优先级并尝试选择一组优先级最低的目标。
仅当移除优先级最低的 Pod 不足以让调度程序调度抢占式 Pod,
或者最低优先级的 Pod 受 PodDisruptionBudget 保护时,才会考虑优先级较高的 Pod。
kubelet 使用优先级来确定
节点压力驱逐 Pod 的顺序。
你可以使用 QoS 类来估计 Pod 最有可能被驱逐的顺序。kubelet 根据以下因素对 Pod 进行驱逐排名:
首先考虑资源使用量超过其请求的 BestEffort 或 Burstable Pod。
这些 Pod 会根据它们的优先级以及它们的资源使用级别超过其请求的程度被逐出。
资源使用量少于请求量的 Guaranteed Pod 和 Burstable Pod 根据其优先级被最后驱逐。
说明:
kubelet 不使用 Pod 的 QoS 类来确定驱逐顺序。
在回收内存等资源时,你可以使用 QoS 类来估计最可能的 Pod 驱逐顺序。
QoS 不适用于临时存储(EphemeralStorage)请求,
因此如果节点在 DiskPressure 下,则上述场景将不适用。
仅当 Guaranteed Pod 中所有容器都被指定了请求和限制并且二者相等时,才保证 Pod 不被驱逐。
这些 Pod 永远不会因为另一个 Pod 的资源消耗而被驱逐。
如果系统守护进程(例如 kubelet 和 journald)
消耗的资源比通过 system-reserved 或 kube-reserved 分配保留的资源多,
并且该节点只有 Guaranteed 或 Burstable Pod 使用的资源少于其上剩余的请求,
那么 kubelet 必须选择驱逐这些 Pod 中的一个以保持节点稳定性并减少资源匮乏对其他 Pod 的影响。
在这种情况下,它会选择首先驱逐最低优先级的 Pod。